![Your Comprehensive Guide To Mobile Game Server Costs [Updated for 2026]](/images/blog/mobile-game-server-costs-featured.webp)
A detailed breakdown of mobile game server and infrastructure costs, covering IaaS, PaaS, and SaaS tradeoffs, Metaplay's architectural design decisions, and practical guidance for budgeting your game backend from first production deployment through to scale.
When talking with our customers, we're often faced with the seemingly simple question of how much they should expect to budget for their game backend servers and infrastructure. It's an entirely valid question, but frustratingly one which has only one real answer: it depends.
This is our first stab at kicking off what will hopefully be a discussion about why the area is so unclear. We'll draw back the curtain on what actually makes up the infrastructure that runs modern games, reviewing how architecture decisions impact not only costs and bottom-line, but also affect what's possible on the creative side of game design.
You'll come away with ideas and concrete tools for answering the main questions around cloud infrastructure and game server costs at scale.
Who is this article for?
You'll find this discussion useful if you're working directly on (or with others) on higher-level game and business decisions. The intention here is to also help studio founders (both technical and non-technical) - particularly those starting out on a new game with mass-market ambitions - to make more considered decisions when it comes to efficient infrastructure design.
That said, the points we tackle here are useful for just about anyone working in games, technology or software. Technical details are discussed, but we try to keep the content on a level that's accessible to non-technical team members too.
Useful background reading
At this point, it would be remiss not to shamelessly plug our colleague, Teemu Haila's, insightful article Ship Fast without Regret. His framework for anticipating the evolving tech needs of a growing mobile game is another lens into the world of making intelligent tradeoffs, and you can consider this article more as an infrastructure view into the same fundamental story. Ready? Let's dive in.

The evolution of game servers
Yours or someone else's computer?
When we're talking about game backends, the most obvious starting point are servers: those mystical, angular boxes stacked on top of each other in some data center on the outskirts of town.
But what exactly is a server? What does a server need to be able to do when it comes to running a mobile game at scale?
To run a game backend you need three things: a computer, storage, and networking.
And not too long ago, in the days before ubiquitous access to virtualized cloud platforms, someone would have to actually figure out the physical side of the servers that hosted these capabilities and ran their games. They'd have to break down the costs of compute, storage, and networking alongside the prices of actual bare metal servers. They'd need to find somewhere to put their servers, figure out the CAPEX budgets for acquiring the devices and the OPEX budgets for the data center space together with the CFO, and factor in other costs like cooling, electricity, network connectivity, and so on.
It was a messy and complex job that required the involvement of many stakeholders before you could even think about getting started.
And then cloud computing came along.
The cloud vendor renaissance
The cloud renaissance started with the advent of virtualization and the spawn of cloud vendors. These essentially were third-parties capable of selling on-demand access to the basic resources we mention above, billing initially by the hour (but now by the second).
There's an old adage in tech: that the cloud is just someone else's computer. And while that adage has received a fair amount of flack, at its core it does still hold true: you either own your hardware yourself, or you buy the equivalent capacity of resources from someone else - i.e. a cloud vendor.
On the face of it, it's a simple premise. But the picture clouds a little with the introduction of different abstraction layers (e.g. "do I get a virtual machine that I run my MySQL database on or do I just get access to a platform which provides me a MySQL backend?" and "with serverless compute I no longer need to know anything about Linux!").
These abstraction layers essentially spawned a host of *aaS abbreviations designed to offer different services for different needs, with an array of possibilities on pricing and customisation capabilities.
The birth of IaaS, PaaS and SaaS left game developers and software engineers facing a number of tricky tradeoffs on how to most effectively and efficiently set up their infrastructure stack - and it's those we're shedding some light on today.
The Rise of IaaS, PaaS, and SaaS in Game Server Infrastructure
To understand the server and infrastructure costs for mobile games today and the decisions facing developers as they set up their infrastructure stack, it's useful to take a look at the various types of services supporting these requirements, and how they've evolved over time.
What is Infrastructure-as-a-Service (IaaS)?
Infrastructure-as-a-Service (or IaaS) came first, which was essentially the virtualized, programmatic, just-in-time and on-demand access to the basic resources around servers, storage, and network.
What is Platform-as-a-Service (PaaS)?
Platform-as-a-Service (or PaaS) is the evolution of IaaS. PaaS essentially hides those individual infrastructure components behind more abstracted interfaces. It allows the consumers of PaaS services to focus more on application-level issues, and not get too concerned about the intricacies of what goes on inside those platforms.
To concretize this a bit more, with IaaS you often get blank canvases in the form of virtual machines with an operating system. This allows you to manage them in pretty much any way you want, and gives you the maximum amount of flexibility, but the tradeoff is the complexity in setting them up and ensuring that they work and scale as they should.
PaaS, on the other hand, often takes applications or services that you could set up and manage yourself on top of IaaS and instead does that all for you, taking away the operational overhead and complexity of IaaS. Although you don't need to care that much about servers, you still have to consider things such as execution environments and versions, and manage the applications that consume the PaaS.
However, PaaS introduces the tradeoff of typically costing more per unit of usage than if you built everything yourself. PaaS solutions also often impose certain limitations required for the vendor to be able to provide you with a more simple and scalable platform.
In short, PaaS gives you less control than IaaS, but is easier to manoeuvre. However, that often comes at a cost of being more expensive than IaaS.
What is Software-as-a-Service (SaaS)?
The third big *aaS is Software-as-a-Service (SaaS). SaaS is the most mass-market version, and kicks the abstraction layer up a notch again.
Comparing SaaS solutions to PaaS, SaaS moves the boundary more towards offering only interfaces or APIs to a software service, which is fully run and managed by the SaaS vendor.
All that said, the boundaries between these categories are fairly vague, and sometimes it comes down to just a matter of perspective of how to classify different services. And when setting out to build your game, the boundaries are so blurred that it often makes sense to mix and match (i.e. you don't need to exclusively choose IaaS solutions - it's more than fine to mix IaaS components with PaaS, and in many cases in fact makes a lot of sense).
Of course, a major distinction between each of these types of solutions is pricing. Choosing between IaaS, PaaS and SaaS has huge implications when it comes to how much it costs to run a mobile game. We'll get to that now.

Breaking down the cost of a mobile game backend
How PaaS, IaaS, and SaaS Cost Dynamics Compare
We already alluded to the cost dynamics between IaaS, PaaS, and SaaS, but it may be worthwhile to tease out more concrete examples.
We will have to do some generalizations, and counter-examples can always be found relatively easily, but some ways of capturing the differences are noted in the table below:

Should You Prioritise Control, Cost, or Ease-of-Use in Your Game Server Stack?
The general dynamic is that the higher the abstraction level goes, the more costly the unit of consumed resource becomes. At the same time, the indirect cost from active management required goes down.
That means the more actively you manage and control something, the cheaper it is to run. Conversely, the more abstraction layers there are, then the less control and capability to manoeuvre you have, and the more expensive you can expect it to be.
This of course comes with its pros and cons. If you're cloud infra-savvy then more control at a lower cost is somewhat of a no-brainer. But if you're a relative novice and want to get started fast, then it more than likely makes sense to pay for a more plug-and-play solution that's more expensive.
The most typical example of this would be compute. Buying your own servers is expensive upfront, but excluding cost of humans to operate them, they are by far the cheapest long-term way of running compute. Virtual machines by cloud platforms (i.e. IaaS) are slightly more expensive, but are still considered a commodity, although they again require someone to look after them. You'll also need to know what you're doing in order to set these up - something we explore in greater detail later.
With PaaS, you start entering the world of managed container platforms, serverless compute, and similar topics, for which the cost goes up even more. And at the far end, with SaaS, the metrics for what you are paying for might have changed altogether.
How Much Do Game Server Compute Environments Cost?
To put some numbers to these, let's assume that we need a relatively small, 4 vCPU server with 16 GB of memory and 100 GB of storage. While estimating server sizing in practice is difficult, we typically start with an estimate of around 1000 concurrent users per core. This would take us to around 4000 concurrents, or about 200,000 daily active users.

The above example is slightly contrived, but illustrates in a very rough fashion the dynamic of how the cost of a compute environment would behave if we strip it down to a toy example, while ignoring that each of these approaches has different sweet spots where they'd be used.
It's clear that when it comes to compute, IaaS is our cheapest option, but let's break down each of these costs in more detail.
Using a physical server for compute
For example, a rack-mountable, entry-level server with these specifications would cost around 1000-1500 euros.
Using AWS EC2 instance for compute (IaaS)
m6i.xlarge instance (4 vCPU, 16 GB) at 0.192 USD/hour + 100 GB EBS gp3 storage at 0.08/GB-month.
1 month cost: 138.24 USD for instance and 8 USD for storage = 146.24 USD/month.
Using AWS Fargate for compute (IaaS)
CPU: 0.04048 USD/vCPU/hour, memory: 0.004445 USD/GB/hour, storage: 0.000111 USD/GB/hour.
1 month cost: 116.58 USD for CPU, 51.21 USD for memory, 7.99 USD for storage = 175.89 USD/month.
Using AWS Lambda for compute (PaaS)
Billed primarily by memory, we'll assume we want 2 Lambda functions at 8 GB per function running continuously at 0.0000001333 USD/1ms.
1 month cost: 691.03 USD for functions, 8.01 USD for storage.
How Much Does Game Server Observability Tooling Cost?
Another example could be observability tooling, specifically Prometheus (Prometheus is widely used for metric aggregation and as a data source for visualizing metrics and other time series data.)
In this example, an infrastructure stack for a big game backend might include 300,000 active Prometheus time series, with every metric scraped once per 10 seconds. This is the type of load you would be expecting to see in a very large scale game with multiple millions of daily active users.
For the sake of the example, we will consider three approaches: self-managed Prometheus (IaaS), AWS-managed Prometheus (PaaS), and Grafana Cloud (SaaS). Again, you can clearly see that the IaaS solution is by far the cheapest option when it comes to how to set up your observability tooling.

Using IaaS for observability tooling
Starting with IaaS, we empirically observe this amount of load to consume around 1 vCPU and around 3-6 GB of memory. The storage varies based on the amount of data retention, but we can assume that 200 GB should be sufficient for covering a couple of weeks of data retention at this sample size.
These specs could be satisfied by an m6i.large, which would cost 0.096 USD/hour or 69.12 USD/month for the instance itself. The storage would be around 16 USD/month for a total of about 85.12 USD/month.
To keep the example simple, we will assume data transfer costs to be small based on the target metrics being scraped from close proximity.
Using PaaS for observability tooling
For the AWS-managed Prometheus, the main cost drivers are the amount of samples ingested, metric storage, and querying.
With the same number of active time series (300,000) being scraped once every 10 seconds, we ingest about 77.76 billion samples per month. Ingest pricing is 0.9 USD/10M samples for the first 2B samples and 0.35 USD/10M samples for the next 250B samples, putting our ingest costs at 2,831.6 USD/month.
With the same 200 GB storage as above, storage costs would be 6 USD/month. Querying costs 0.10 USD/B samples processed, but we won't delve into that here.
Using SaaS for observability tooling
Finally, Grafana Cloud charges 8 USD/1000 active series at 1 minute interval. Reducing the scrape interval to 10s would conversely increase costs by 6-fold. With our example case, the 300,000 active series would thus cost around 14.4k USD/month.
Of course this is again a fairly superficial example and not an entirely apples-to-apples comparison. Each of the approaches has its own tradeoffs and the numbers are not fully comparable, but they are sufficiently in the ball park to illustrate the underlying dynamic in a case where the consumed resource is a metrics platform.
Another takeaway from this example is that even though the IaaS approach is drastically simplified, the fact it's much cheaper than the alternatives does allow ample room to architect a more robust and scalable solution if we only factor in the operational costs.
How Much Do Game Server Engineers Cost to Hire?
To round off the series of examples, we should understand the cost of labor. Alongside pizza and beer, engineers often require other forms of payment as well, often in hard currency.
This is again a subject which varies greatly depending on many factors, including seniority and geographical location. But a lazy and easy to calculate approach would be to assume that in Finland a competent cloud engineer would cost perhaps 100,000 EUR annually, including side costs.
With careful geographical selection, this can of course be brought down meaningfully, or by going to Silicon Valley the costs can go up equally meaningfully.
The key point here is that the less abstractions you use in the stack (i.e. choosing IaaS or PaaS services and components over the likes of SaaS) the more you will need to build and operate yourself, and the more you will end up spending money on staff and time in recruitment and management of teams.
Metaplay's architectural and design decisions

So what does any of the above mean to you in the context of game backends? How do we know whether we should go with IaaS, PaaS, SaaS, or some combination of the three when designing our infrastructure stack?
The biggest thing to consider is that everything is a tradeoff with pros and cons. These influence how we think and approach the design of game servers, as well as the underlying architecture of the stack that allows those game servers to run.
Let's relate this back to our own infrastructure design. From the outset, Metaplay's objective has been to build an offering that is scalable to very large games. This means making technology choices in a way which allows us to be as efficient as we can be, while not making sacrifices in important areas.
In no particular order, the list below gives a subset of design considerations we've had since day 1:
- The game server design has to be massively scalable: we must be able to demonstrate easily the ability to serve millions of concurrents. The technology must be proven in action so customers do not have to refactor when scaling up their games.
- The design must be economically efficient: the variable costs that correlate most with increased player counts must have a shallow slope (i.e. small marginal cost). We tolerate some increased complexity if it allows us to achieve lower unit costs at scale.
- Avoid vendor lock-in where possible, and only sacrifice on this if we achieve something more valuable instead. Prefer open, industry standard technologies to make recruitment and operations easier.
- Minimize complexity for game developers: Make the daily operations of the infrastructure and game as easy as possible while attempting to minimize compromises on other objectives.
- The game studios must be able to concretely own all their data all the time.
There are arguably a much longer list of additional considerations that we have been carrying with us over the years, but these capture the core principles of our thinking.
However, we are still quite abstract, so let's dive into some more concrete examples around what we've designed and why, and how it fits into the broader cost discussion.
(A word of warning that the discussion gets a bit more technical here, but if you're not a server engineer then fear not - we're not here for too long.)

Why Stateful Game Server Design Can Be More Cost-Effective
One of the biggest defining characteristics of our backend design is the stateful nature of Metaplay servers.
While the predominant view in the world for the past decade has been to favor massively scalable, stateless backends due to their simplicity and relative ease of operations, we felt that in the context of games, there are even bigger victories to be won by looking at stateful designs.
This in practice means that the actor-based approach of modeling games puts the individual game servers as the authoritative source of state after an actor, be it a player, a guild, or some other artifact, has been woken up from the database. And after the initial wakeup, data will only periodically be persisted back into the database to avoid data loss. And all actors can converse with each other within the clustered game server backend.
The most obvious criticism for this is naturally that scaling can become a bit more involved. However, what we achieve with this design is massive efficiency gains and the ability to offer a more powerful framework within which you can design long-running actors.
One angle of the efficiency gains comes from reducing the database to the role of a more simple, slightly glorified key-value store. Every single operation or action in the game no longer needs to make a call back to the database, reducing the load on databases significantly.
As an example, instead of the more common 9-to-1 ratio on read to write operations, we more often see a 1:1 ratio, meaning that you do not need to run those 8 extra read replicas. We also support scaling the database layer out by sharding into multiple database clusters to ensure that we do not hit the ceiling when scaling a database cluster up.
This design decision also simplifies our architecture further. When database performance becomes an issue, a common strategy is to often apply an in-memory caching system like Redis or Memcached. In our architecture, we can omit these components fully - our game server application layer already does the work, by ensuring the actors are always the latest, up-to-date state of the world.

Cherry-Picking Compute: How to Balance Cost and Control with Kubernetes
As we discussed above, often the cheapest form of compute is available as IaaS. This is also the approach that offers the most flexibility and control (e.g. if you want to do UDP on AWS Lambda or get access to a wonky execution environment to take ad hoc memory dumps).
IaaS means that under the hood, the game servers are running on virtual machines. That said, due to operational reasons, we would much rather not spend too much time and effort in monitoring and observing the health of virtual machines.
This is why, despite consuming IaaS virtual machines, the orchestration and coordination of them is left to dedicated components like Karpenter - and all virtual machines get registered to Kubernetes.
The tradeoff here is the increased complexity that Kubernetes brings to the table. Anyone who has ever worked with Kubernetes can attest to the constant evolution of the platform and the running it requires to even stay in the same place.
However, at the same time, Kubernetes is an increasingly compelling and extensible container orchestration platform, and allows us much easier and granular control over the stateful payloads that we run.
All the above leads us to a balancing act where we want the control and cost-efficiency of IaaS compute, but we will gladly consume the Kubernetes control plane as a PaaS service offered in the form of AWS Elastic Kubernetes Service (EKS). Piggy-backing off of the latter, we outsource the control plane, operations, and updates to AWS for a fixed price of about 72 USD/month/cluster for this ease of mind.
But why not Lambda?
We occasionally get asked why we do not use AWS Lambda or similar serverless functions. By this point the stateful nature of our payloads should offer the main clue to this.
Additionally, because of the rather constant stream of actions being processed by game backends and potential long-lived nature of actors, serverless functions tend to not be the ideal execution platform.
Lambda also requires a minimum execution context of at least 128 MB of memory and has traditionally had non-zero wakeup times. So for our core payloads, AWS Lambda is not an optimal solution.

Why Persisted Game State and Data Integrity Is Critical
We already alluded to it earlier, but in our simplified worldview the most important item in the backend is the game data, which in our case lives in MySQL.
In the same manner as with Kubernetes, managing MySQL clusters is something that we would rather not do ourselves, and we would also suggest our customers not to do either. So instead of IaaS, we take the PaaS approach here and leverage AWS's Aurora MySQL backend.
This not only gives us much more peace of mind in knowing that it just works, but also that it provides us tools simplifying operations like backups, recovery, and rollbacks.
This decision is further supported in our mind by the easy integration with the broader ecosystem of tooling that AWS has in the form of AWS Backup, which allows us to also easily back up other key resources in our stacks.

Ensuring Observability and Openness in Your Game Server Stack
As discussed above in the example of costs, auxiliary systems like logs, metrics, and tracing can get fairly expensive fairly quickly in the event that PaaS/SaaS systems are used. But it is a critical area and absolutely necessary when operating, developing, and debugging software.
Typically, the more data and higher granularity that can be achieved will directly impact the ability for technical teams in reacting to issues quickly, which further guides our decision to prefer solutions which allow us to ingest larger amounts of data while keeping the financial costs low.
We also recognize that observability tooling area is an area which is very opinionated. This makes it a good example of where we apply the philosophy to trying to find not only the right balance between how to consume some set of tools, but also leave open the side door to allow an opinionated customer to easily deactivate and move to using something entirely different.
While our default infrastructure stack relies heavily on tools like Prometheus, Grafana, and Loki, we also make it easy to opt-out of them and instead configure data collectors (log collectors, metric scrapers) to send data to a third-party location.
We realize that especially bigger organizations might already have an observability solution in place which their operations teams use, and in cases like these we want to make the integration as easy as possible.
Now you've a better understanding of the infrastructure design choices we've made at Metaplay, let's look at the implications they have in practice, both when it comes to cost and usage.
Going into production for the first time with Metaplay's tech stack

We've extensively talked about tradeoffs, how to think about cost dynamics on a high level, and how Metaplay approaches infrastructure. But you probably want to address going into production with your game and what all this means to you.
Alongside Metaplay's SDK and the other technologies that you've been developing with locally, Metaplay also offers a reference infrastructure stack in the form of Terraform modules. This offers an easy path for our customers to start deploying their own infrastructure stacks in AWS.
We believe this is a good starting point, considering the objectives and tradeoffs described above. That said, we let customers easily pick apart our stack and re-engineer it to their own preferences.
Ultimately, we assume the ability to:
- Run Docker containers in a sensible way
- Publish internet accessible endpoints
- Have a data persistence layer in the form of MySQL and S3 compliant endpoints
And maybe a few other items, but as said, we strive to be as in line with commonly accepted industry standards as possible.
But, assuming that we're going with our reference stack and starting from scratch, we have typically ball-parked a basic infrastructure stack that is capable of production operations to cost around 650 USD/month.
The reason why an empty stack that you own and operate yourself and which does not go to zero in price is (you guessed it) because of the above decisions around IaaS versus PaaS and which tools we've selected. But we'll use the rest of this chapter to go through as an example what that 650 USD/month breaks down into.
$650 a Month: Breaking Down Metaplay's Production Server Costs
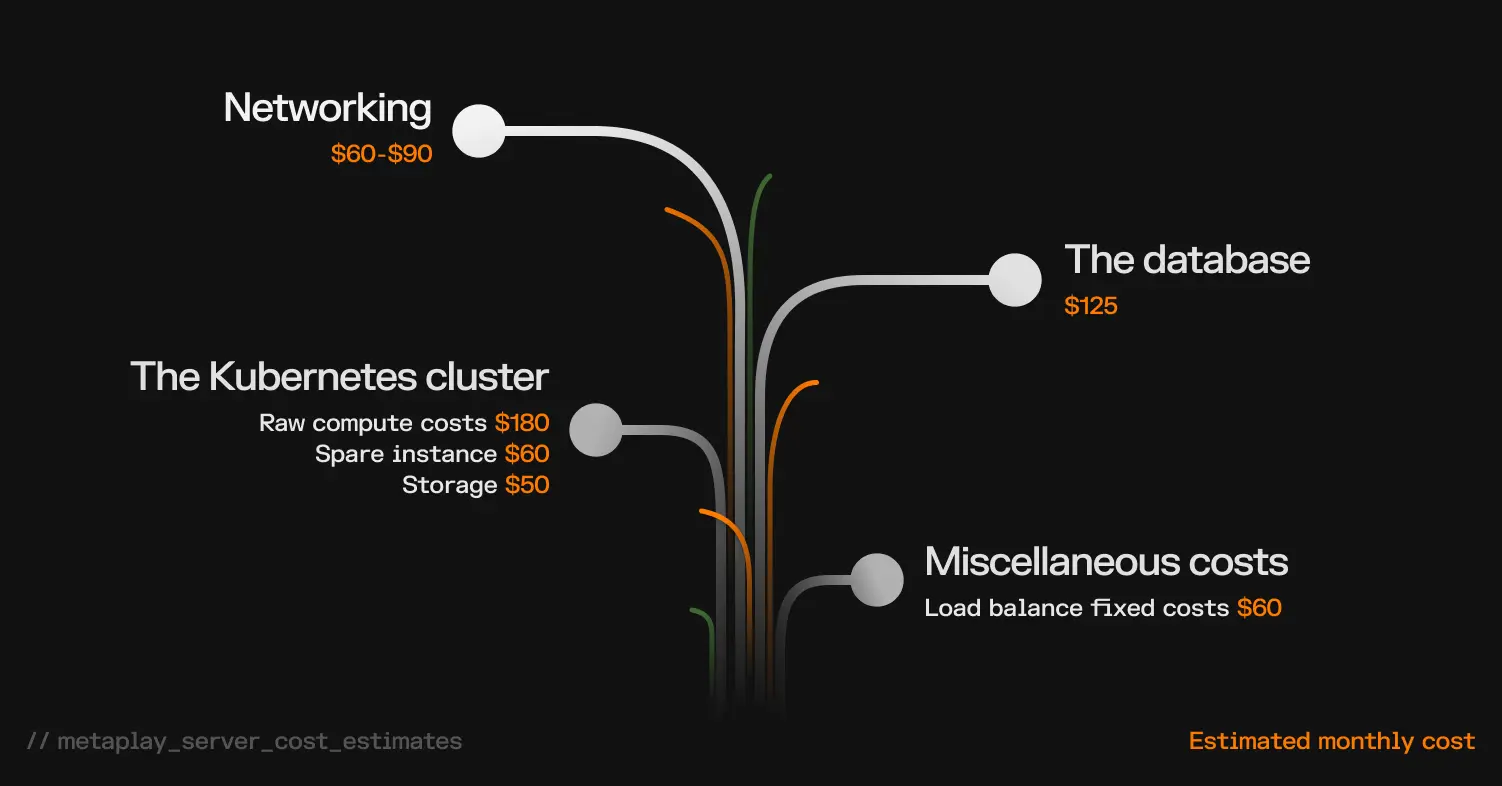
Server cost #1: Networking
At the core of everything is networking. While VPCs and routing tables and security groups are free, the major fixed cost we have to endure here are NAT gateways.
These are around 30 USD/month/gateway, and as per good cloud engineering practices, you should always spread your workload over multiple availability zones within a single region to minimize risk of disruption due to a single availability zone outage.
NAT gateways are the route your infrastructure uses to communicate with the rest of the world, and you'll need one per availability zone (typically 2-3 availability zones will be sufficient, so the fixed costs on aggregate are 60-90 USD/month).
Server cost #2: Database
Our base production stack is expected to run a single Aurora MySQL database cluster in a two replica configuration, one for read-write operations, and the other for read operations and acting as a hot-standby.
At a minimum, we typically suggest using at least a db.t3.medium instance sizing to get going with, which puts the costs at a bit over 60 USD/month/instance, or around 125 USD/month for the pair. We assume storage and I/O to be negligible at these types of initial launch sizes.
Server cost #3: Kubernetes cluster
As discussed, we leverage AWS EKS as the Kubernetes control plane, which is the brains behind the container orchestration. AWS charges 72 USD/month/cluster, and we need one.
In addition to this, we need the compute for running not only the game server, but also the supporting tooling. Taking these separately, the supporting tooling typically starts off at around 3-4 2 vCPU and 8 GB memory instances, such as t3.large or c6i.large. This gives us the ability to run highly available and fault tolerant setups of our supporting tooling, with room to grow in capacity before having to scale out further. This puts the raw compute costs at around 180 USD/month.
There's also room to optimize this by reducing redundancy slightly, but as we're talking about a beginner production setup, it's often easier not to aim for those minor cost savings, and instead have a bit of a buffer.
The game server compute sizing itself is a tricky subject, and we can discuss empirical rightsizing of infrastructure using load test strategies. But, if doing a small launch, typically a relatively small instance is sufficient to get you across the initial launch.
We like to isolate game server workloads to run on their dedicated instances to minimize risks from noisy neighbors and reduce possible blast radius. We also suggest running a plus 1 hot spare instance in case of instance degradation, which is useful to save time. We can ball park these costs at around 60 USD/month.
Finally, we need some block storage for the instances. This can be approximated in the above setup to be around 50 USD/month.
Other miscellaneous server costs
The final fixed costs from our basic stack come from two load balancers: one for generic Kubernetes cluster HTTP ingress and the second for TCP load balancing for the game server connectivity. Load balancer fixed costs are around 30 USD/month/load balancer, for a total of about 60 USD/month.
The rest of the costs originate from Route53 DNS zones, AWS Secrets Manager secrets, S3 buckets, Cloudfront distributions, and so on, but for a very small scale stack, these costs are negligible.
Summary: What a Minimal Production Game Server Stack Costs
So if we put all of these together, we get around 650 USD/month of costs, give or take.
These are unoptimized costs that can be reduced with typical tactics around Reserved Instances and Savings Plans for some additional savings by those who are competent in doing so, but for practical purposes, the above illustrates a minimal setup that allows comfortable operations of a Metaplay backend.
Many of the costs are also to a degree fixed and difficult to get rid of altogether.
Why Minimal Fixed Costs Beat Zero-Usage SaaS Pricing for Games
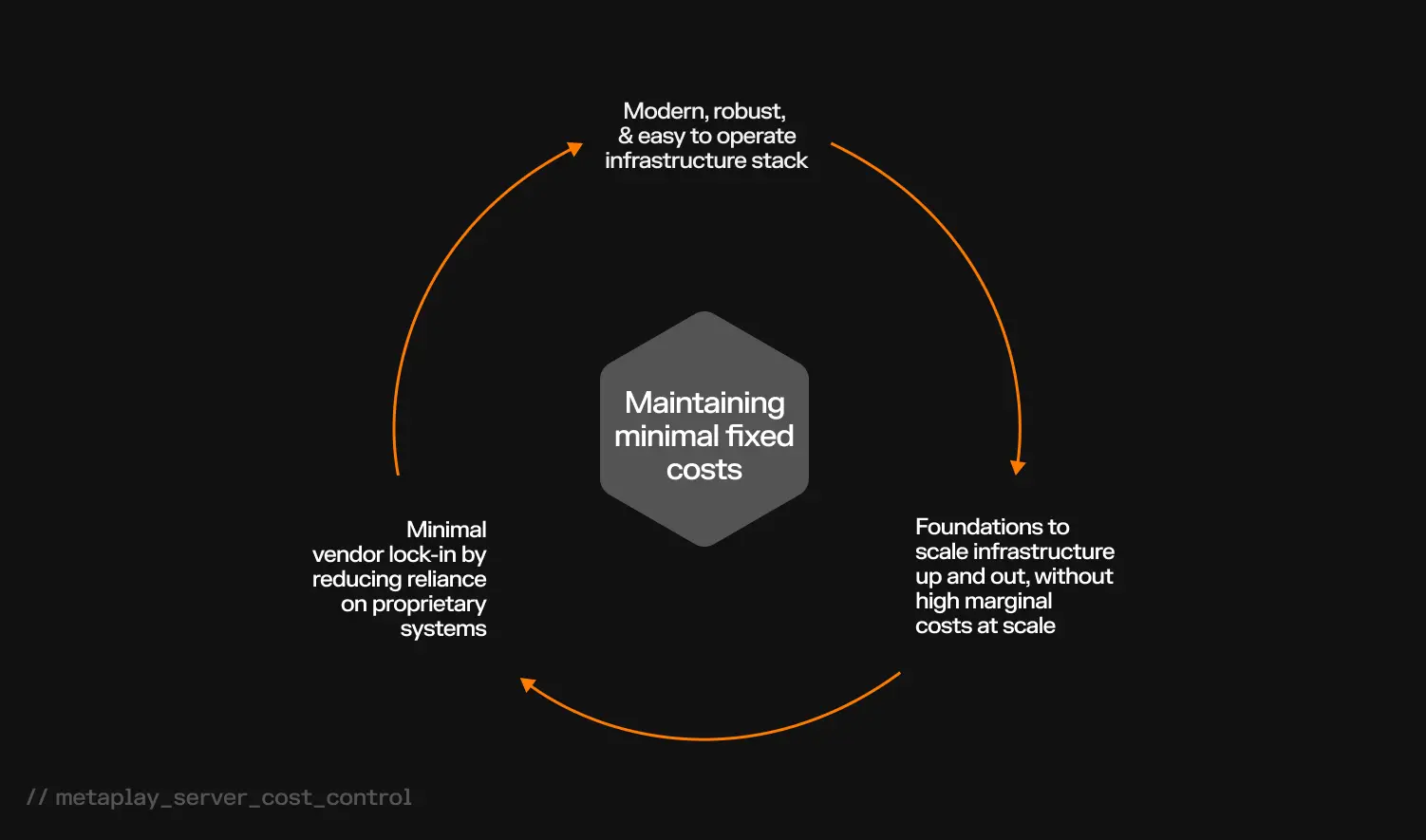
For those more accustomed to a SaaS type of pricing model where zero usage goes to zero costs, this type of minimal fixed costs-model may be somewhat surprising.
Our reasoning, however, is that this approach strikes a balance of allowing us to simultaneously design a modern infrastructure stack which is reasonably easy to operate yourself, is robust enough to tolerate common error conditions, and strives to minimize vendor lock-in by not relying particularly heavily on any proprietary systems.
And that's all while still laying the foundations for allowing you to scale up and out as your game grows. Importantly, it also means you won't have the immediate regret of getting stung by high marginal costs at scale that many SaaS platforms have built into them.
As an extra cherry on top, this type of stack setup allows also relatively easily running it in multi-tenant mode. That makes it entirely feasible to take a stack like this and running multiple different game server environments on it, for example as development environments. In these types of cases, extra redundancy can be reduced to bring down the per-environment unit costs to very reasonable ranges.
The next step: Running infrastructure at scale
Now that we've tackled what a barebones stack and associated costs look like, what about running game backends at scale?
While it's fairly straightforward to describe the cost structure of a minimal stack, the situation changes at scale when the characteristics of games start driving the costs more. Some games may be more simulation-heavy and require much more in the form of compute resources in the backend. Other games might be very content distribution heavy, which would put meaningfully more financial strain on storage and bandwidth costs needed to distribute assets.
With the understanding that every game is different and that it's hard to make any sweeping generalizations or give any ballpark figures, we can still use this chapter to cover some observations and considerations in larger scale deployments. Additionally, we can talk a bit about tools and tactics that are available to attempt to cut through the uncertainty and complexity as a game grows.
How Do Cloud Costs Change as Your Game Scales?
Keeping in mind our discussion on the barebones stack, the costs there were based largely on fixed costs (hourly prices that you cannot fully get rid of). These are very typical when operating at a small scale, and while they take up a proportionally large part of the invoice at the beginning, in absolute terms they're still relatively small.
When scaling up, however, other cost drivers emerge that eclipse these fixed costs.
Additional cost #1: The database layer
We can consider for example the database layer. At small scale the instance costs are clearly the key driver of cost. It's not unreasonable to say that in the beginning, instance costs effectively make up all the database costs.
However, as games start scaling, you will see a necessary increase in instance costs - either through scaling up database instance sizes, other costs from I/O pricing, or from backup/snapshot storage.
Additional cost #2: Load balancing
A similar pattern emerges for load balancing: at small scale the load balancers are essentially a fixed cost. However, at scale, that fixed hourly cost becomes minor compared to the costs from load balancer "capacity units". Capacity units are AWS's way to aggregate the work done by a load balancer, capturing multiple dimensions ranging from throughput to connection counts.
In some cases, we have also seen content distribution costs become quite high compared to the costs of the rest of the stack at scale - even reaching sizes of almost a quarter of total infrastructure costs.
Why Cloud Costs Can Diminish at Large Scale
Having said this, there are some positive observations to remember:
- In the greater scheme of things, these costs are often relatively minor
- Cloud and infrastructure costs can diminish at large scale
- Most of the rising costs discussed above can be solved through optimization of the following:
- Data retention policies (i.e. more frequent data destruction = less data storage = lower costs)
- Cold storage can be utilized
- Alternative content distribution providers can be utilized
- Financial planning can be improved via Reserved Instances or Savings Plans
Best practices for reducing infrastructure costs at scale
We've discussed that cloud costs naturally increase as your game scales. The IaaS/PaaS approach that we take here at Metaplay is designed to keep a lid on that to a degree, while we're also mindful of other best practices when setting up our infrastructure stacks. Let's look at a couple of them:
Prioritize Quality Code to Reduce Infrastructure Costs
Developing a game locally and running it for a small technical demo audience is wildly different than running a game that's played by hundreds of thousands of people every single day.
Quick and sloppy prototyping can often be tolerated at the beginning of game projects. And that's understandable: the benefits from spending extra time optimizing your code are small compared to being able to quickly demonstrate new game mechanics to test out retention numbers or pass funding gates.
However, when scaling up a game, these types of shortcuts together with quality assurance issues can be one of the single biggest drivers for increasing costs. While this area is not strictly speaking only in the domain of cloud infrastructure, it's highly relevant to understand and consider when evolving and maturing a game production - and the organization that runs it.
Keeping player models tight, code paths optimized, and memory management under control means less compute resources, and less costs as you grow.
Leverage Load Testing for More Accurate Cost Estimates
An excellent tool in understanding resource consumption at scale is carrying out realistic load testing against the game. This is true for any backend project, and there are various tools available, but in the Metaplay ecosystem one that we particularly like is our bot client framework.
This allows you to easily build bots which mimic action patterns of real players, and we provide tooling to help run bot clients at large quantities.
Running bots, besides being heaps of fun, help us in two crucial ways:
- Hunting down regressions before they hit production
- Understanding the impact of new features and functionality on resource consumptions
For cost estimation, running load tests are easily the best way of getting meaningful cost estimates while taking into account the nature of the game. These load tests are also convenient for capacity planning ahead of time.

Cloud server costs: Final takeaways
So now that we've extensively covered infrastructure, associated costs, and how we think about the various design and tradeoff decisions, as well as touching lightly on the world around the stacks, what are the key takeaways from all of this?
I'll try to summarize in no particular order the key points:
- Estimating costs and resource consumption is a tricky business and very dependent on the nature of the game, the scale at which it's being operated, and how much the infrastructure and the game itself are optimized.
- In general, cloud costs are a game of tradeoffs. There is never a singular, globally optimal strategy: Metaplay attempts to curate an opinionated solution for stateful game backends which utilize a combination of IaaS, PaaS, and SaaS, depending on what makes the most sense in specific sub-problems.
- The ways in which costs manifest themselves changes over time, as scale and specific problems evolve.
- A better way to get realistic cost estimates is through empirical testing, for example through representative bot client-based load tests.
That just about brings our first discussion of cloud infrastructure and server costs for mobile games to a close. And while there is no concrete answer, we hope you've taken away from it some best practices you can apply to your own project - or at least some points of contention that you'd like to argue with us about!
FAQ
How much does it cost to run a mobile game server?
A basic production infrastructure stack capable of supporting a mobile game launch costs approximately $650/month with Metaplay's architecture. This covers networking (NAT gateways), database (Aurora MySQL), Kubernetes cluster (EKS), compute instances, storage, and load balancers. Costs scale from there based on your game's specific resource consumption patterns.
Should I use IaaS, PaaS, or SaaS for my game backend?
The best approach is typically a mix. IaaS provides the cheapest compute but requires more management. PaaS reduces operational overhead at higher unit cost. SaaS is the most abstracted but most expensive per unit. Metaplay uses IaaS for compute (via Kubernetes on EKS), PaaS for databases (Aurora MySQL), and allows flexible observability choices.
Why does Metaplay use a stateful backend design instead of stateless?
Stateful design reduces database load dramatically - achieving a 1:1 read-to-write ratio instead of the typical 9:1, eliminating the need for read replicas and in-memory caching layers like Redis. This yields significant cost savings and architectural simplification while supporting long-running game actors like players and guilds.
How can I estimate my game's infrastructure costs at scale?
The most reliable method is empirical load testing using bot clients that simulate real player behavior. Metaplay provides a bot client framework for this purpose. Running load tests helps identify resource consumption patterns specific to your game, enabling more accurate cost projections than theoretical estimates alone.


![Revealed: The True Cost of Building Your Own Game Backend [Updated for 2026]](/images/blog/the-true-cost-of-building-your-own-backend-featured.webp)
![Best Practices For Reducing Infrastructure Costs at Scale [Updated for 2026]](/images/blog/best-practices-for-reducing-infrastructure-costs-at-scale-featured.webp)